Summary of the Article
Have a project in mind?
Schedule a CallOptimizing Data Through Indexing: Unlocking the Power of Efficient Data Retrieval

Summary of the Article
Introduction
Indexing is a robust database method that can significantly enhance query performance and increase overall system efficiency. Indexes allow quick data retrieval, sorting, and filtering processes by organizing data into organized data structures. This blog will discuss the idea of indexing, its advantages, different types of indexes, factors to take into account when using indexes effectively, and best practices to enhance database performance.
What are Indexes
Indexes serve as a guide for quickly finding data inside a database. They function by building a unique data structure that associates key values with the precise location of the related data. This enables the database system to conduct focused searches based on the indexed columns rather than scanning the full dataset while performing queries. Indexes make it possible to quickly retrieve data and enhance read operations’ overall performance.

How Index Table is Created
In a database, the creation of an index table, also known as an index structure, is a built-in process that occurs when an index is created on a specific column or set of columns. When you create an index on a table, the database management system automatically generates the corresponding index table.
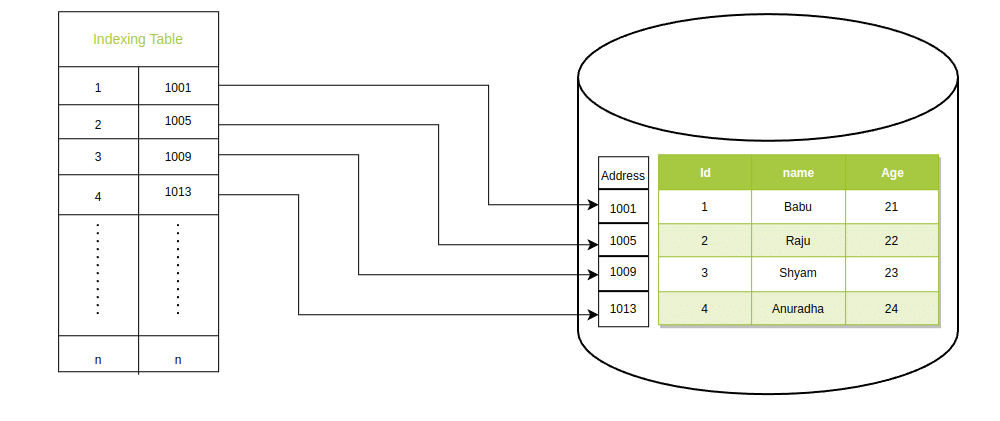
The above Image is showing how the index is created its own data structure in Primary storage
Types Of Indexing
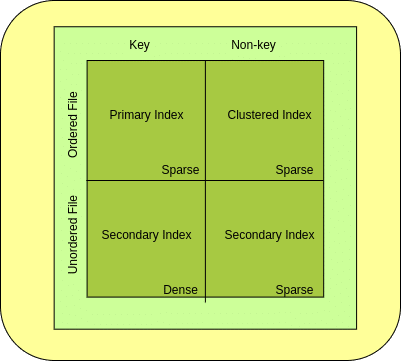
There are several types of indexing techniques used in databases, each tailored to different data structures and query patterns. Here are some commonly used types of indexing:
-
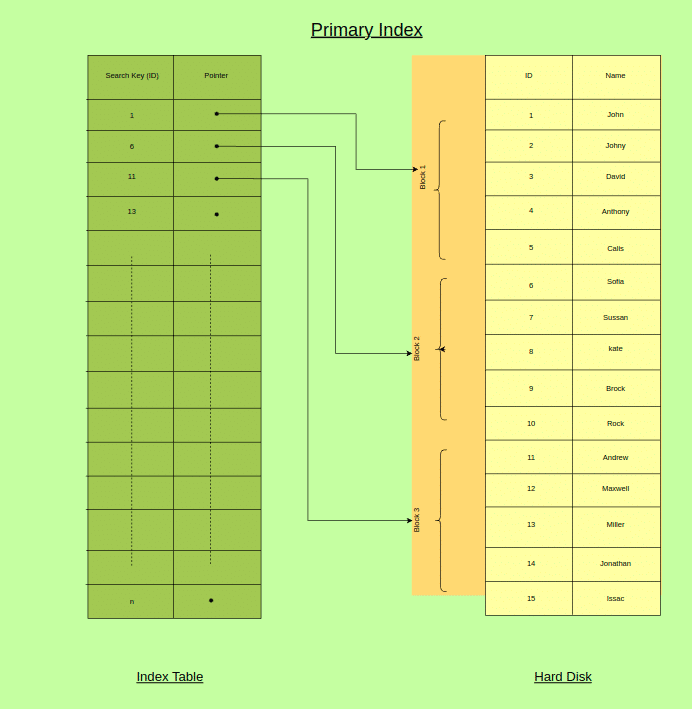
Primary Index:- The practice of making indexes using a table’s main key is known as “primary indexing.” The primary index is a fixed-length, sorted file with two fields: the first field contains the primary key, and the second field has an address referring to a specific data block. Searching is quite efficient since the primary keys are preserved in sorted order. To further comprehend the primary index, let’s look at an example.
-
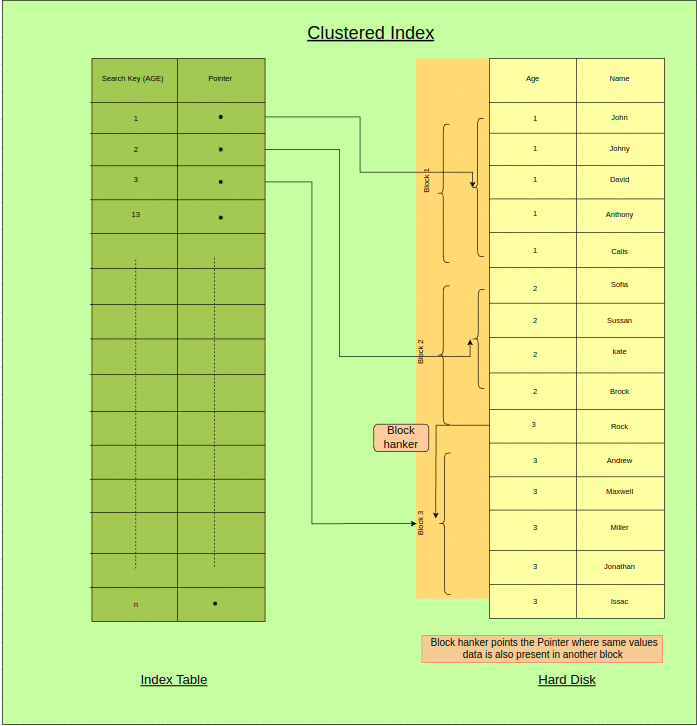
Clustered Index:- A database’s clustered index type establishes the actual arrangement of data rows in a table. A clustered index, as opposed to other sorts of indexes, directly controls the order in which the data is saved on the disc. Other forms of indexes store the index apart from the table data.
-
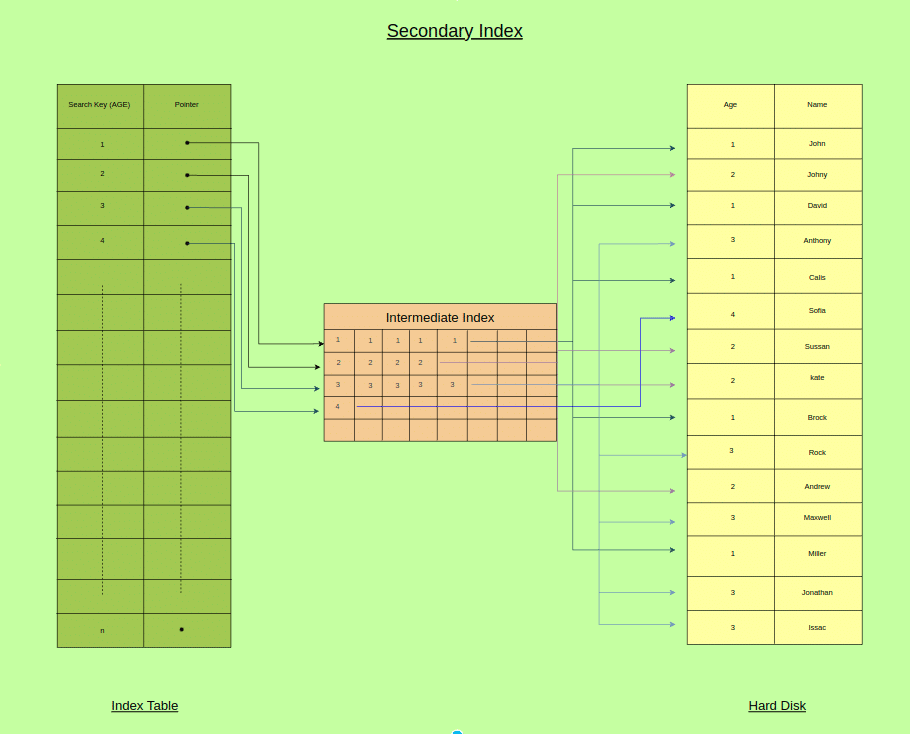
Secondary Index:- A secondary index, sometimes referred to as a non-clustered index, is a database data structure that offers an additional access route to the information kept in a table. A secondary index, as opposed to a clustered index, which specifies the physical order of data rows, enables effective retrieval based on one or more specified columns without requiring a full table scan distinct structure is created by the secondary index to link the indexed column(s) to the relevant data location(s) inside the table. This improves query performance by allowing the database system to easily discover and get data based on the indexed column(s). Reduced disc I/O and quicker response times can benefit queries that use the indexed column(s). Multiple secondary indexes may be present in a table.
Understanding Different Scan Types in Database Queries
Indexes are fundamental components of databases that improve query performance and data retrieval efficiency. Different types of indexes are used in databases, each catering to specific data structures, query patterns, and optimization goals. Here’s a detailed explanation of common index types used in databases
-
Index Scan: Effective retrieval with the use of indexes utilizing an index structure to access data appropriate for selected queries by accessing necessary data pages, reduces I/O costs.
-
Index-Only Scan: Direct retrieval from the index, avoiding table access, is possible with an index-only scan reduces I/O overhead and boosts efficiency index must have requested columns favorably affecting queries with a subset of columns.
-
Bitmap Scan: Combining indexes with bitmap operations in a bitmap scan efficient under scenarios involving complex query bitmaps are utilized to represent matched rows. Fast intersection, union, and exclusion operations are made possible.
-
Parallel Sequential Scan: Scanning the table in parallel with several processes or threads uses many CPU cores to speed up the scan Possibility of parallelizable scans for huge tables needs a machine with enough resources and is configured properly.
-
Sequential Scan: Performing a sequential scan of the full table There is no usage of indexes to retrieve data. Large part or full table suitable
Commonly used index structures
Index structures refer to the specific data structures used to organize and store indexes in a database. An index structure determines how data is organized, accessed, and searched within an index. The choice of index structure can greatly impact the efficiency and performance of data retrieval operations.
-
B-Tree Index: B-Tree (Balanced Tree) index is the most widely used index type in databases. B-Tree indexes organize data in a self-balancing tree structure. They are efficient for equality matches and range queries. B-Tree indexes maintain sorted order, enabling fast search, insertion, and deletion operations. They work well for columns involved in sorting, searching, or join operations. B-Tree indexes are commonly used in relational databases like PostgreSQL, MySQL, Oracle, and SQL Server.
Example: A B-Tree index on a “last_name” column in an employee table can speed up searches for specific last names or range queries. -
Hash Index: Hash indexes use a hash function to map keys to specific locations. They are optimized for exact matches and provide constant-time lookups. Hash indexes are well-suited for scenarios where equality comparisons are prevalent. However, they are not suitable for range queries or pattern matching. Hash indexes are commonly used in some NoSQL databases, in-memory databases, and specialized scenarios.
Example: A hash index on a “product_id” column in a product table can efficiently retrieve information about a specific product. -
Bitmap Index: Bitmap indexes represent data presence/absence using bitmap vectors. They are effective for multi-value or categorical columns with low cardinality. Bitmap indexes support efficient intersection, union, and exclusion operations. They excel at complex query conditions involving multiple criteria. Bitmap indexes are commonly used in data warehousing and analytics databases.
Example: A bitmap index on a “gender” column in a customer table can quickly identify all male or female customers. -
GiST (Generalized Search Tree) Index: GiST index is a versatile index type supporting a wide range of data types and operators. GiST indexes are used for specialized data structures, such as geometric shapes or custom types. They enable efficient search and retrieval for complex data types. GiST indexes provide various search strategies and allow customization through operator classes. GiST indexes are commonly used in databases like PostgreSQL.
Example: A GiST index on a “geometry” column in a spatial database can enable efficient spatial queries, such as finding points within a specific area.
-
GIN (Generalized Inverted Index) Index: GIN index is designed for full-text search, array containment, and composite types. GIN indexes perform inverted indexing, allowing efficient search within arrays or composite data. They are effective for scenarios involving complex queries on array values or full-text searches. GIN indexes are commonly used in databases like PostgreSQL.
Example: A GIN index on a “tags” column in a blog post table can enable quick searching for posts containing specific tags.
Where to use Indexes
-
Huge Datasets: Indexes are very helpful when working with huge datasets since they can significantly shorten the time needed for data retrieval and querying.
-
Search Operations: Indexing particular columns can greatly speed up query processing if they are regularly utilized in search operations, such as WHERE clauses.
-
Performance-critical Queries: Use indexes to ensure speedy response times and effective data retrieval for queries crucial to your application’s performance.
-
Primary and Unique keys: The columns that include primary keys and unique constraints should both have indexes built on them. Data integrity is ensured by indexing these columns, which also enhances query efficiency when looking for special values or executing.
-
Sorting and grouping: Sorting and grouping processes can be optimized by building indexes on the columns that are used in your queries when sorting or grouping data. Indexes make it easier for the database system to locate and arrange the data in the appropriate order.
-
Foreign key: Foreign key columns can improve the efficiency of joint operations by being indexed in tables. Indexes on the foreign key columns make it possible to look up and get related data more quickly when tables are joined based on foreign key relationships.
-
Text Search and Full-Text Queries: Using full-text indexes can significantly improve search operations on text-based data if your database supports full-text search functionality. Full-text indexes make it easy to quickly search through vast text fields for particular words or phrases.
Advantages of Indexing
-
Searching, Sorting, Group by For Records:
SELECT * FROM Employee WHERE Salary > 65000 AND Salary < 81000
In the above example, we can see the SQL SELECT statement benefitting from the index in the Salary column. The index sorts the salaries in ascending order. The SELECT statement uses these indexes to identify and separate the records with a salary between 65000 and 81000.
-
Efficient Data Filtering: Indexes enable efficient filtering of data based on specific criteria. When a query includes conditions on indexed columns, the database can utilize the index to quickly identify the relevant data rows.
-
Faster Joins: Indexes facilitate faster join operations between tables. By indexing the columns involved in join conditions, the database can perform efficient index-based lookups and merge the relevant data from multiple tables, improving the speed of join queries.
-
Maintaining a Unique Column: We often work on primary keys in SQL. Unique indexes apply to primary key columns that require unique values. There are different ways to create a unique index. One of the ways is to mark a column as the primary key. A primary key column has a unique index on the column automatically created on it. Another way is by checking the CREATE UNIQUE checkbox that gives a unique index to the specified column.
-
Optimized Disk I/O: Indexing reduces disk I/O operations by providing direct access paths to the data. Instead of scanning the entire table, the database can navigate the index structure to locate the desired data, minimizing the amount of data that needs to be read from the disk.
The trade-off of Indexing
-
Increased Storage Overhead: Indexes require additional storage space to store the index structures. As the size of the indexed columns increases, so does the size of the index.
-
Higher Insertion, Deletion, and Update Costs: Maintaining indexes incurs overhead during data modification operations.
-
Index Maintenance Overhead: Indexes need to be regularly maintained to ensure their accuracy and efficiency. As data is inserted, deleted, or updated, the index structures must be updated accordingly.
-
Increased Complexity: Indexes introduce complexity to the database system. Managing multiple indexes, and dealing with index fragmentation.
In conclusion, indexing plays a crucial role in optimizing query performance and improving data retrieval efficiency in databases. By creating appropriate indexes on the relevant columns, you can significantly enhance the speed of data retrieval, reduce query execution time, and improve overall system performance. We explored various index types, such as B-Tree, Hash, GiST, and more, each designed to cater to different data structures and query patterns. Additionally, we learned about the advantages of indexing, including improved query performance, efficient data retrieval, enhanced data integrity, and support for constraints and joins. However, it’s important to strike a balance between the benefits of indexing and the associated trade-offs, such as increased disk space and maintenance overhead. Careful consideration of index design, regular index maintenance, and monitoring performance metrics are essential for optimizing database performance. By leveraging the power of indexing, you can unlock the full potential of your database and ensure fast and efficient access to your data.
Certainly! Here are some potential open-ended questions that encourage critical thinking
-
When working with large production databases, how do you determine which columns to index, and when is the right time to create indexes?
-
Considering the nature of blob data or large column data, what challenges or considerations should be taken into account before creating an index on blob columns?
-
As tables in a database grow, the size and performance of index structures become crucial. How do you handle sizing and managing index structures when the table size increases significantly?
Explore the idea of indexing, its advantages, different types of indexes, factors. Give a click on VT Netzwelt to learn about the best practices to enhance database performance.
Frequently Asked Questions
What are Indexes?
Indexes are data structures used in databases to improve the speed of data retrieval operations, such as searching and sorting. By storing a sorted reference to the data, indexes enable the database engine to quickly locate and access specific records without scanning the entire dataset. This optimization technique enhances query performance and reduces latency, making it crucial for efficient data management and retrieval in large-scale applications.
How Index Table is Created?
Where to use Indexes?
How can we encourage critical thinking through open-ended questions?









